Update 2017-04-14: Since I pubbed earlier today, a Marketo PM noted that the underlying (mis)behavior is a bug that'll be fixed eventually. I always considered it a bug, too, but assumed it was here to stay. Either way, folks affected need a workaround for now. I'll update when the post is officially obsolete.
Yep, I said only!
So not

but

OK, if you're absolutely sure that all possible values will display correctly, use a native {{lead.token}}. But I'm 100% sure you can't be sure. :)
What the — howzat — huh?
A fundamental cause of overconfidence and confusion is that the Email Editor lies to you (unintentionally). I'll show you how it happens, using this imaginary test lead, Thérese-Björn 张:
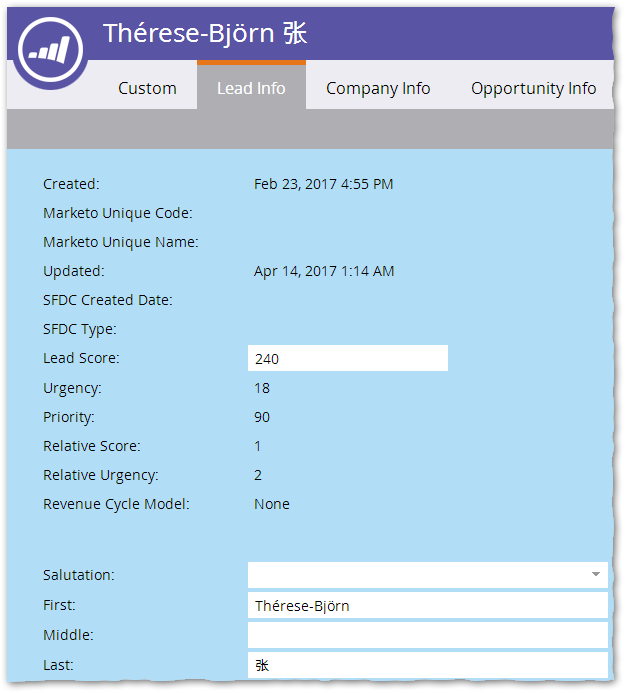
Note how Thérese has two Latin-1 (i.e. not in the simplest ASCII set, but not Unicode-only) accented characters é and ö in her First Name and a Unicode 张 in her Last Name. (Obviously, this is intentional to highlight the issue!)
Let's see how the Editor previews a simple tokenized Subject:

Now let's look at how that subject really looks in an email client, in this case Gmail in Chrome:

OK, now I see it!
Thought you would.
What you're seeing here is an unintended consequence of enabling the (otherwise very good, and still recommended) HTML Encode Tokens feature in Field Management:
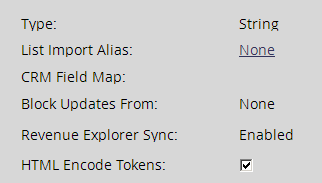
Don't just leap to unchecking this checkbox. As I'll show below, it performs a critical function. But in Subject lines, it becomes harmful.
Why? Because, as we learned in my post on emojis, Subject lines are ASCII-only. Even when the Subject appears to support accented and Unicode characters…

… it really doesn't. They're still Q-encoded as basic ASCII by the mail sender and then decoded silently by the mail reader app.
Mail apps tend to hide the fact that this encoding/decoding is happening, thinking (?) it's for your own good. Even in Gmail's View Original Message you'll still see “Thérese-Björn 张.” But then click Download Original Message and you'll see what Marketo really sent:

It's super-frustrating that two different variations are both termed “original.” Anyway, the second one is the actual one sent out. You can see the Q-encoding plain as day.
(Another example of a mail app glossing over how Subject-sausage is made is that the Marketo Preview is misleading. By skipping over the encoding/decoding process that the underlying email infrastructure must do, it implies that stuff works when it doesn't in the real world. Sure, é dsiplays as the desired é in Preview, but that's because the Subject box is literally an HTML <DIV> at that point, not an SMTP header.)
Don't bring HTML to a Q fight (or something like that)
But in order for Q-encoding to work, the tokens can't already be encoded as HTML entities. If they're entities like é then Q-encoding is just going to encode those 8 literal characters (& e a c u t e ;), having no idea it was supposed to be a French e with accent aigu.
As I've mentioned in other posts, when you use the wrong encoding for the job, you get gibberish (perhaps a better term is “unspecial stuff”). Just as HTML entity encoding has no place in a Subject line, Q-encoding has no place in, say, a PowerPoint. There, it's just a meaningless assortment of question marks, letter *Q*s, and = signs.
So the reason that HTML-encoded {{lead.tokens}} don't work in Subject lines is simple: Subject lines neither support, nor discard, HTML &entity; codes. They see them as text, so they get printed as-is.
Why not just turn off HTML encoding?
Because you'll break other stuff.
See, the reason the HTML Encode Tokens setting exists is because if you just output raw token text into HTML (like the body of an HTML email), you can break the HTML.
There are 5 super-special characters (" ' < > &) that are lying in wait to break your HTML, and several more that will break it under certain circumstances. (Accented Latin-1 characters pose almost no risk in this regard, but it's not possible in Marketo to leave those alone and only encode the known-dangerous ones.)
And since you aren't able to validate all inputs, somewhere in your database (maybe tons of places) I guarantee you have token values that will break output if they're not encoded.
Take a lead that has their Job Title set to <Compliance Director> (note the greater than and less than signs). If you output {{lead.Job Title}} in an email and it's not encoded, you'll get this:

That's not the string value “<Compliance Director>” you're looking at: it's an unknown HTML tag <Compliance> with an attribute Director! As such it will never be printed. You'll just get a blank between the words “New” and “jobs.”
Of course that's not the only way to break HTML if you don't encode. How about someone who works for Joe's Barbershop. Consider what happens when that token is output into this HTML snippet:
<a href='http://www.example.com/company?{{Company.Company Name}}'>Get your specials</a>
The effective link will be:
<a href='http://www.example.com/company?Joe'>Get your specials</a>
If you were planning to parse the company out of the URL, you're out of luck.
Lest you think you'd fix this by switching to double-quoting the attribute, what about people that work for Jilly's "Best Cookies in Town" Bakery? (Note these are both cases where Velocity-based URL-encoding is the right fix, but at least with HTML-encoding you'd get a whole string.)
The point is, there are many ways for token values to break HTML, and only one way to stop them.
The solution
As the post's title suggests, leave HTML Encode Tokens turned on, and use a Velocity token that outputs your lead token if it needs to go in the Subject. A one-line token as simple as
${lead.FirstName}
solves the problem because Velocity gets the raw, unencoded value and can decide to output it as-is. (Velocity can also flexibly HTML- or URL-encode output if you choose, so it's a better all-purpose solution.)