Being paranoid about encoding — URL encoding, HTML encoding, UTF-8 encoding, any encoding — helps avoid uncomfortable post-mortems.
But here’s one type of apparent encoding bug that’s actually a false alarm.
Been working with a client on a complex Marketo form localization project, where pretty much everything — from labels to placeholders to error messages to dropdown options — is translated according to the perso n’s selected language.
There’s only one form defined in Marketo, with a separate translations file (a JS file to be hosted on their CDN) for each language.
I provided download links to the client, but they wrote back with alarm: “When we open those URLs, we don’t see Chinese characters. The file encoding must be wrong.”
But nothing was actually wrong! They were just, without realizing it, looking at the the files in a context that the real world doesn’t use.
You see, they were just opening https://assets.example.com/translations/simplified-chinese.js directly in Chrome, which looks like this:
But if you save the underlying file and open it in a text editor, it clearly has the right encoding to support the CJK characters (in this case, UTF-8):
And it also works fine when actually loaded on their Landing Page:
<script src="https://assets.example.com/translations/simplified-chinese.js">
</script>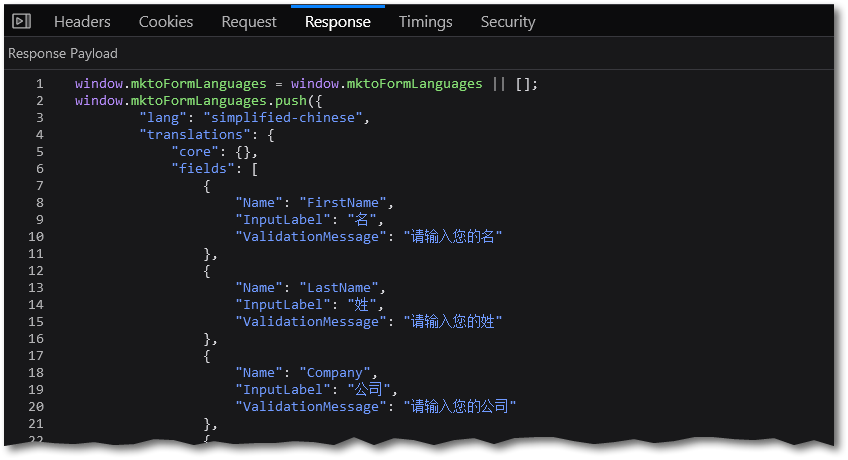
Why does it look garbled when you open the JS file directly? Because CodePen (where I put the files for them to download) doesn’t let you set UTF-8 encoding at the MIME header level. That is, it sets Content-Type: application/javascript, not Content-Type: application/javascript; charset=utf-8:
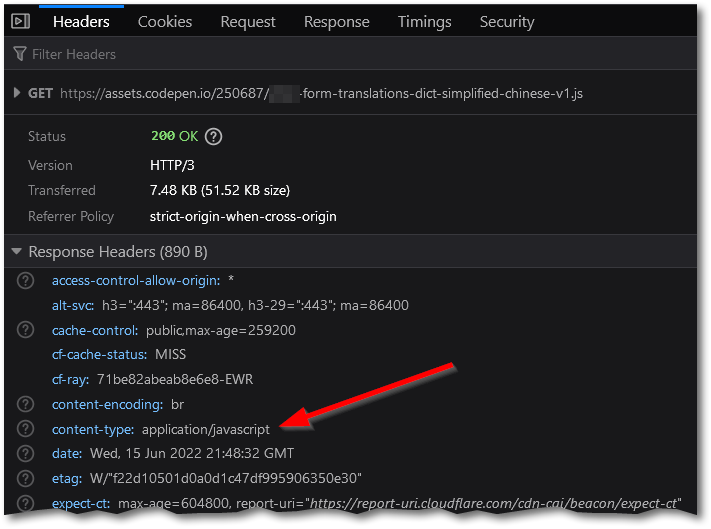
As a result, the browser tries to guess the encoding automatically:

But it, well... is terrible at guessing. It thinks the data is in ISO-8859-1, even though it’s UTF-8. (ISO-8859-1 is so out of date in 2022 that it’s a weird default, but it comes from age-old compatibility worries.)
Firefox’s View menu gives you the rather oddly named Repair Text Encoding feature (which, even more oddly, appears to be greyed out even though it works):
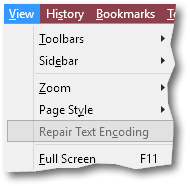
Clicking Repair for this particular file enabled Firefox to parse it correctly as UTF-8, but to be honest I’m not sure how reliable that would be on other files.
In any case, both Firefox and Chrome initially guess that files without an explicit charset are ISO-8859-1, which is why they may appear garbled. But don’t worry!
This doesn’t matter in real life
The reason you mustn’t worry about this particular behavior is it only applies when you peek at the JS file in its own tab, not when the JS file runs nor when you download the file to your machine.
The HTML standard is clear that the src of a <script> tag is assumed to be in the main document’s encoding. As of HTML5, the document encoding defaults to UTF-8. Even if you set it explicitly, you’re only allowed to set it to UTF-8 using either the new-school or old-school <meta> tag syntax:
<meta http-equiv="Content-Type" content="text/html" charset="UTF-8">
<meta charset="UTF-8">Therefore, when viewing a real webpage, it’s impossible for any modern browser to interpret the remote JS file as anything but UTF-8 — even if the server hosting the script doesn’t specify the encoding, and regardless of how the script content appears in its own tab.
Final thoughts for techies
It’s best for servers to set the header Content-Type: application/javascript; charset=utf-8 if they’re sure that’s the correct encoding.
But then you’re in the realm of manual setting vs. automatic detection. How do you set the encoding of a single static file on a webserver? Not easy if it’s a file on disk and doesn’t have a BOM or any other place to set its metadata. You’d have to write a special config rule for each file.
Conversely, if you were to send application/javascript; charset=utf-8 for all files ending in .js, then you’re guessing. Maybe some files are in ISO-8859-1 or UTF-16. These wouldn’t be appropriate for use in a web page, but you’re certainly allowed to send JS files around using these encodings.
So it’s not too weird that CodePen leaves off the encoding entirely. Inconvenient but understandable.