Many APIs return data structures that are pretty wacky, at least relative to how you want to process the data in your app. The property names and values are all there in the response, yes — but it's just not quite right.
Case in point: the Google Sheets API.
Take a Sheet like this:
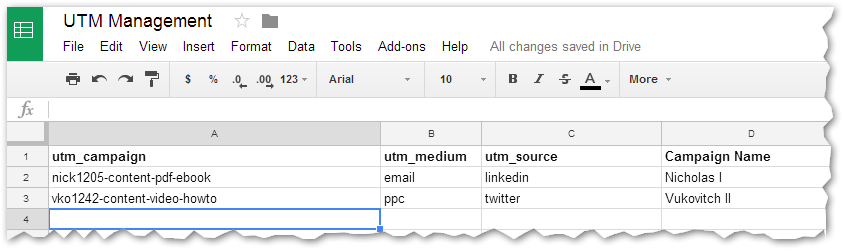
When you fetch that Sheet via API, the response is undeniably accurate[1], yet far from ideal for further processing.
var sheetsResponse = {
"range": "Sheet1!A1:D1000",
"majorDimension": "ROWS",
"values": [
[
"utm_campaign",
"utm_medium",
"utm_source",
"Campaign Name"
],
[
"nick1205-content-pdf-ebook",
"email",
"linkedin",
"Nicholas I"
],
[
"vko1242-content-video-howto",
"ppc",
"twitter",
"Vukovitch II"
]
]
}
Yes, this format[2] is
- self-explanatory
- space-efficient
- necessary due to JSON's limited datatypes (as we'll see in another post)
but it's also
- utterly frustrating from a programming standpoint
You can't easily grab Row 2's utm_medium, for example, since each data row is an array of values only, with no references to the column names in the header row.
(Since the column order can easily change, rows[1][1] isn't always the utm_medium. You need to get correct data regardless of whether someone makes a change to the sheet layout.)
You can stare at structures like this for awhile, thinking, “How do I pivot this to be more usable, without introducing new spaghetti code of my own?”
There's no question that JavaScript array functions can transform the format any way you want; how to do it elegantly is the question. Writing short-and-sweet-and-readable code to translate between formats is a great way to flex your JS skills.
What's a better shape for the same data?
Let's think about the format we'd prefer for simple seeks and searches. It would (IMO) be something like this (in pseudo-code):
row [0] =
[0] utm_campaign = "nick1205-content-pdf-ebook"
[1] utm_medium = "email"
[2] utm_source = "linkedin"
[3] Campaign Name = "Nicholas I"
row [1] =
[0] utm_campaign = "vko1242-content-video-howto"
[1] utm_medium = "ppc"
[2] utm_source = "twitter"
[3] Campaign Name = "Vukovitch II"
... etc...
Now we're talkin', right? An ordered set of ordered key-value objects, where each sheet row is an object is easy to navigate.
We can seek by row number (again, in pseudo-code, not JS):
SecondCampaignName = rows
→ item(1)
→ get('Campaign Name')
Search by column value to find another value in that row:
NicksCampaignName = rows
→ findFirst(row)
→ where(
row → get('utm_campaign') → equals('nick1205-content-pdf-book')
)
→ get('Campaign Name')
Or find the row number itself:
VukosRow = rows
→ findFirst(row)
→ where(
row → get('Campaign Name') → equals('Vukovitch II')
)
→ get(row index)
It'd be easy peasy.
So how do we get the original array of generic arrays into a far better array of key-value objects?
(Note I didn't say “array of capital-O Objects” since we haven't yet locked down a particular datatype. Being able to directly access row.column.value is the goal; the best object type, as we shall see, may not be the generic Object.)
First, splice the outer array
It's clear that we need to segregate the header rows from the data rows, so:
var columnNames = sheetsResponse.values[0];
This sets columnNames to only the first array in the array-of-arrays, the values like utm_campaign, utm_medium, and utm_source:
[
"utm_campaign",
"utm_medium",
"utm_source",
"Campaign Name"
]
Then the data rows are all the remaining rows:
var dataRows = sheetsResponse.values.splice(1);
Now dataRows is an array-of-arrays, but it only contains rows 2 and after, like
[
[
"nick1205-content-pdf-ebook",
"email",
"linkedin",
"Nicholas I"
],
[
"vko1242-content-video-howto",
"ppc",
"twitter",
"Vukovitch II"
]
]
So we're doing a little better already, but there is still far to go.
Second, assemble the objects
To create the objects we want, we need to pair each item in the array of column names with the same column position (i.e. index) in each array of data values. I call this a synced iterator, meaning that as we iterate through indexes 0, 1, 2 etc. in Array A, we move to the same index 0, 1, 2 in in Array B. Here, A is the headers; B is the data.
Yes, we could for-loop over each array and get it done. But I prefer to use JavaScript's built-in iterator methods, like forEach, map and reduce. (Again, it's not like there aren't many acceptably good ways to code this up. It's about choosing one that is concise, elegant, and — one must admit — fits personal preferences.)
What not to do
Now, here's what we're not going to do. This is a basic function to sync up two arrays to a generic JS Object:
function syncIterators(keyArray,valueArray){
var newObj = {};
keyArray.forEach( (keyItem,idx) =>
newObj[keyItem] = valueArray[idx]
)
return newObj;
}
This function might appear to be fine (try it!). For inputs like this:
var keyArray = ["favorite_fruit", "favorite_team", "favorite_color"],
valueArray = ["apple", "Poets", "magenta"];
syncIterators(keyArray, valueArray) will result in this Object:
{
"favorite_fruit": "apple",
"favorite_team": "Poets",
"favorite_color": "magenta"
}
Isn't that exactly what we want? No, it is not. Yes, the function fits the general concept of a synced iterator, but has one gigantic flaw when it comes to data like a spreadsheet: you can't correctly reproduce the original data from the result. You can't turn the above Object back into the original Arrays.
“How can that be?” you scoff. “Got the headers, got the data, got all of JavaScript at my disposal. You're telling me I can't turn the keys back into an Array, and the values into another Array?”
That's right, you can't. I believe this is the most common single mistake in JavaScript. Even more than not understanding async stuff and asset loading (the last is browser-related and not JS-related anyway). This is a mistake you have made and you'll make it again. I still slip up myself.
The mistake is forgetting that…
the order of keys in a JavaScript Object is not defined
In the Object above, favorite_fruit, favorite_team, and favorite_color are not the “1st, 2nd, and 3rd” keys in the object. They aren't the anything-th keys in the object. They do not have an order. Even if you insert the keys one at a time, a minute apart, the insertion order is irrelevant.[3] Therefore, the Object
{
"favorite_team": "Poets",
"favorite_fruit": "apple",
"favorite_color": "magenta"
}
holds exactly the same data as the Object above.
It's so, so easy to forget this rule. Say you have an object with lead info:
{
"First Name" : "Sandy"
"Last Name" : "Whiteman",
"Phone" : "(555) 123-4567"
}
You might output it with
for (var i in LeadInfo) {
if (LeadInfo.hasOwnProperty(i))
leadContainer.addText( i + " is " + LeadInfo[i] );
}
expecting to see
First Name is Sandy
Last Name is Whiteman
Phone is (555) 123-4567
but in fact you can't be sure you won't see another order like
Last Name is Whiteman
Phone is (555) 123-4567
First Name is Sandy
You might imagine you'd fix this with Object.keys, since that function returns an (ordered) array of the keys in an object:
Object.keys(LeadInfo).forEach(function(i){
leadContainer.addText( i + " is " + LeadInfo[i] );
})
but this doesn't change anything. Object.keys is defined as returning keys
In other words, the returned array (like all arrays) has a fixed order, but, somewhat confusingly, the source of that order is the underlying object order, which is itself not standardized!
The standard only says that if for...in returns keys in, say, alphabetical order, then in the same JS implementations Object.keys must also use alphabetical order. Or if for...in uses insertion order in that engine then so must Object.keys. But that doesn't mean that there is a guaranteed order across implementations (i.e. browsers and servers).
One way I've screwed up myself is by creating a series of rules from specific to general, say as a permission table by IP address:
{
"1.2.4.5" : "public",
"1.2.*.*" : "password-required",
"*.*.*.*" : "deny"
}
And then I realize: there's no way to scan this Object in such a way as to guarantee that 1.2.4.5 will match the rule at the “top” as opposed to the one that appears to be at the “bottom” because there is no defined bottom or top.
So the problem with a standard Object for data from a spreadsheet isn't that the Object doesn't represent the column names and data accurately, it's that it doesn't (and can't) represent the original column order accurately.
This is totally unacceptable for data that needs to be flushed back into a spreadsheet after modification, since column order is a critical part of the 'sheet concept.
How come it seems to keep insertion order in my browser, though?
Here's the thing: in modern browsers (and server-side JavaScript engines), you'll find that the insertion order is typically used as the iteration order (not so in older browsers).
But this behavior must be ignored as the JavaScript standard mandates that Object keys not be considered ordered. You can write a standards-compliant JS engine that implements every single letter of ECMAScript.Next, and use any order you want for keys.
(It would almost be better, I think, if one major browser aggressively mixed up key order to keep people on their toes. Would lead to lot less of that bad-code-that-somehow-works.)
So if not a generic Object object, what object do we use?
That'll be in Part II, coming soon.
Notes
[1] Don't get me wrong, the format is appropriately concise for traveling over the net. Not repeating all column names, potentially thousands of times, is smart engineering. It's just not very convenient when you want to do anything with the data.
[2] Changing to majorDimension=COLUMNS gives a different not-right format.
[3] Technically, the may be something internal to the browser that distinguishes them based on insertion order, but this cannot be considered from userland, where we must treat the keys and values as identical.