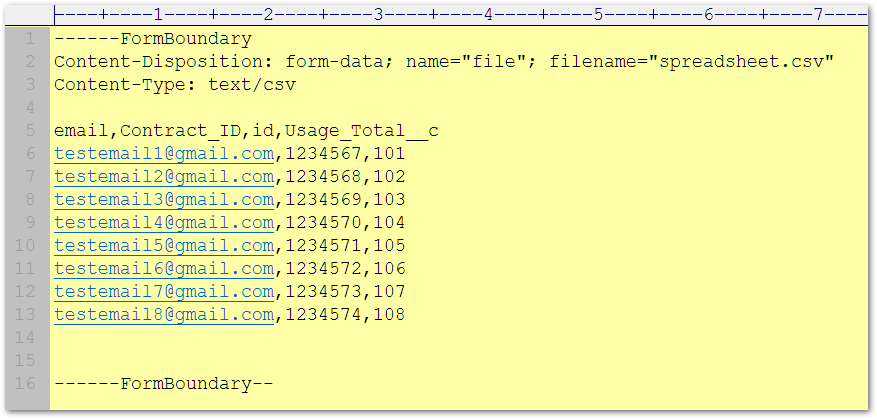
Does this look like good multipart/form-data for the Marketo REST API Bulk Import endpoint?
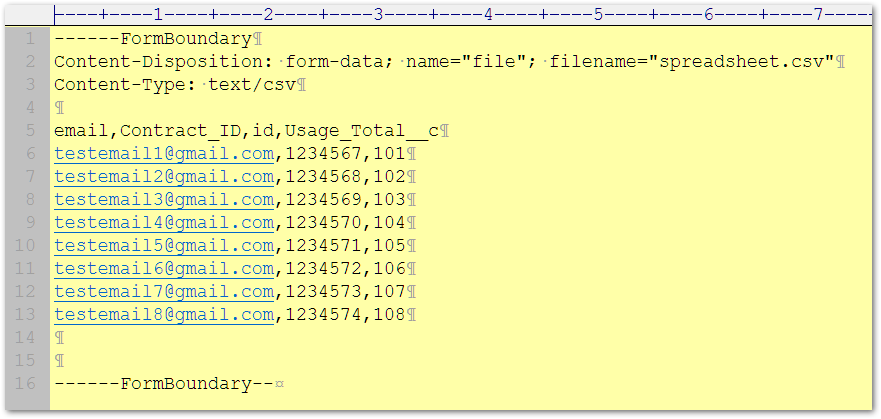
It does, right? Here it is with my text editor (EditPlus) set to show all whitespace, so you can see the CRLFs (represented as ¶) in the right places:
And yet the response from Marketo is:
{
"requestId": "a571#1831bf14ce3",
"success": false,
"errors": [
{
"code": "1006",
"message": "Header field 'email' not found"
}
]
}Strange, eh? The header email is the all-important system field Email Address, that’s definitely its REST API name. In fact, this particular endpoint is lax about case: you can even send EmAiL and it’ll work... at least usually. So what’s different here?
The direct cause
Now, I’ve been deliberately using text editor screenshots to keep you guessing. I was flummoxed myself until I checked the payload in my hex editor (Hex Editor Neo, highly recommended). Some other apps also show you the way. For example, here’s how it looks in WebStorm:
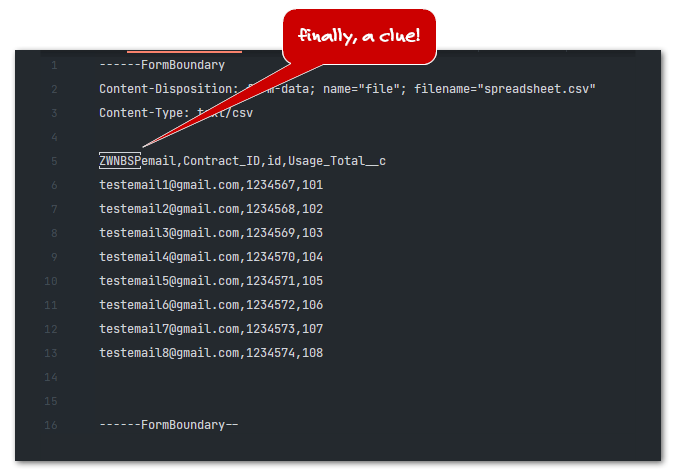
So there is an extra character: what WebStorm displays, correctly-but-not-ideally, as ZWNBSP, Zero Width No-Break Space.
More generally, this is the Unicode code point U+FEFF. EditPlus doesn't classify it as “whitespace”, so you don’t see it there. (They're thinking you want line breaks, tabs, common things like that as opposed to relatively obscure non-printing characters.)
That explains the error: the header is actually U+FEFF followed by the characters e m a i l[1], not just the 5 characters e m a i l.
But this isn’t simply a random character where you chalk it up to a random glitch, delete it and go about your day. If you see it in the payload once, you’re sure to see it again and again, so you need to fix your code to deal with it.
ZWNBSP is another name for BOM
To understand how it gets in there, and why you’ll see it again if you don’t do something, you need to think of its other identity: not ZWNBSP but BOM, Byte Order Mark. In fact, in the Unicode spec you aren’t supposed to use it for no-breaky-ness anymore, but you can still use it for byte order:

Now, I don’t want to dive deeply into byte order today, fascinating as it is. Suffice to say: if (and only if) U+FEFF appears at the very start of a stream of text, it’s called the BOM and determines how the rest of the text is decoded. However, for the type of text that’s supported by the Marketo REST API — that is, UTF-8 text — it’s completely unnecessary (UTF-8 is only ever encoded one way).
Sometimes, if the BOM is present but unnecessary, it’s gracefully ignored (and may be removed when you re-save a file). But in Marketo’s case, sending the BOM when it’s unnecessary breaks everything!
Either outcome is valid, and since you can’t know which one you’ll get with a given app, you should not include the BOM in a UTF-8 payload.
How did the BOM get there?
When you see the BOM within a multipart/form-data part, whoever wrote the code was going for speed over everything. Performance is part of good design, to be sure. But resilience and compatibility need to be covered before you worry about performance.
They likely did something like this, in pseudo-code:
send form-data HTTP headers
send opening MIME data (--boundary,Content-Disposition,Content-Type)
open CSV file from disk
while file chunks remain (
read chunk
send chunk
)
send closing MIME data (--boundary--)They knew the .csv file on disk was already encoded as UTF-8, same encoding they wanted to send to Marketo. So rather than wastefully reading the file into memory and decoding it, only to reencode it into the same sequence of bytes, they just streamed the file as-is to the API.
Now, that’s absolutely the most efficient way to take a file and put it on the wire. It’s silly to peek into file contents where you don’t care about them.
For example, when a webserver delivers a .pdf file, unless it wants to kill its own performance, it doesn’t parse the PDF structure (sections, fonts, embedded images, etc.). It pushes the bytes over the wire, from tip to tail, as fast as possible. It’s up to your device to read and render it, or maybe figure out it isn’t a valid PDF.
But while a PDF is clearly valid or invalid, text files are their own beast. It’s much harder to say what an “invalid text file” would be. In a broad sense (both in and out of Marketo) you’re more likely to end up with mangled text values than, say, a hard error message saying This isn’t a good text file: Import request ignored.[2]
An easy but highly inefficient workaround is to read the entire file, parse it, then put it on the wire again:
send form-data HTTP headers
send opening MIME data (--boundary,Content-Disposition,Content-Type)
open CSV file from disk
parse file, as UTF-8, to one big string
encode and send string as UTF-8
send closing MIME data (--boundary--)That’ll get rid of the BOM but at the cost of both memory and speed. You don’t need to make a drastic move like that.
Instead, you can still stream chunks, but make sure to check the first chunk for a BOM:
send form-data HTTP headers
send opening MIME data (--boundary,Content-Disposition,Content-Type)
open CSV file from disk
while file chunks remain (
read chunk
if chunk is first chunk (
set chunk = chunk without leading EF BB BF
)
send chunk
)
send closing MIME data (--boundary--)Notes
[1] EF BB BF 65 6D 61 69 6C in UTF-8.
[2] Many text encodings seen in the wild (ASCII, UTF-8, ISO-8859-1, Windows-1252, and more) aren’t sufficiently self-describing. Without firm agreement about the expected encoding — take “auto-detection” claims with a grain of salt — you‘ll end up with X% readable text peppered with Y% gibberish.