Warning: this blog post will seem out-of-nowhere until you read the next one, which is a Marketo-focused use for the code supplied below. But this had to come out first in preparation.
Something’s notable about a <style> element with no attributes (no id, no title, no class or custom data-). While the styles inside will work perfectly, there’s no standard way to distinguish the source, purpose, or implied scope of such an element.
Such elements are ridiculously common, of course! You surely have at least one non-attribute-ed <style> in the head of your HTML templates, which you term “local styles.” And 3rd-party libraries can inject many more.
But what if you want to reference a specific one of those stylesheets from JS, like the <style> that brands your video player? Well, you’re basically out of luck unless you get to guessin’.
See, from a DOM standpoint, the element’s inner text is just one big Text node.
Sure, the syntax is supposed to be valid for the language in use[1]. But the browser’s HTML parser doesn’t actually care about that. It’s the separate layout engine that determines the meaning of CSS selectors. As far as DOM methods like document.querySelector("style") go, the inner text is not validated, just like if you had freeform paragraph text in a <div>.
Hold up: Why not just add attributes to the <style> element?
Well, to be frank: duh! If you can add an id or other attribute to the element, you should.
The problem case is when a local <style> needs to be accessed from JS (spoiler: to disable or enable it), but you don’t control how it’s injected into the page.
This is the case with some page/form builders. You’ll have a Textarea where you can add custom styles, but the <style> tag itself isn’t included in the box — that’s added automatically by the platform.
For example, here’s Slides.com’s Custom CSS box:
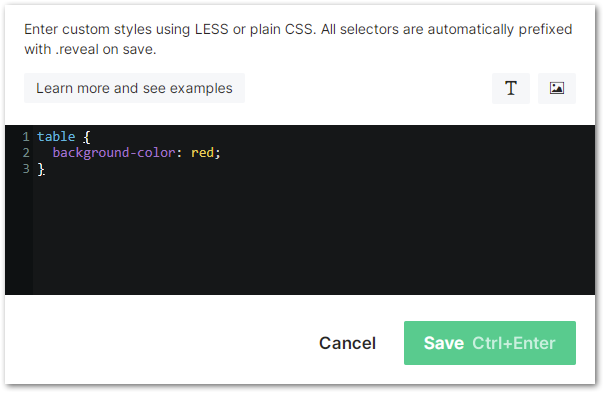
If you try to enter your own <style> tags, that’s a hard error and it won’t let you save:
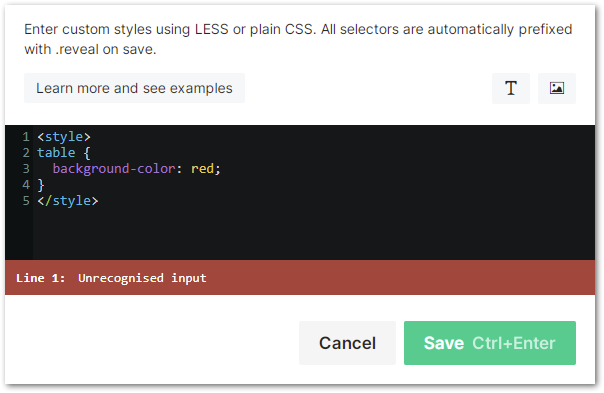
So you need something that goes inside the stylesheet that’s at once:
- reliable/cross-platform,
- in the CSS standard,
- clear (or acceptably so) to the reader,
- non-disposable — i.e. removing it would change the underlying interpretation of the stylesheet — yet also
- guaranteed to not itself affect the styling of any elements
A pretty tricky set of requirements, as it turns out.
OK, back to the project
If you go beyond the DOM and use the CSSOM[2] to take advantage of the CSS parser, you can query the individual rules as objects rather than as free text. For example, this CSS...
#videoPlayer {
background-color: blue;
color: white;
}
#videoPlayer .controls {
border: 3px solid green;
}
... will be transformed into proper CSSRule and CSSStyleRule collections.
cssRules[0].selectorText will be #videoPlayer, cssRules[0].style.backgroundColor will be blue, cssRules[1].style.borderTopColor will be green, and so on.
This is helpful, to a degree, since all values are normalized — whitespace and line breaks in the text won’t affect the parsed CSSOM, a compound border setting is identical to setting border-color and border-style separately, etc.
But it’s still not enough to identify the <style> tag over time, for the pretty obvious reason that there are are infinite ways of ending up with the same final styles, let alone infinite ways to change styles. Expecting people to never change the way a video player elements are styled, just so you can always find the <style> element, is pretty silly!
I considered a comment that’s meant to never be removed:
/* video player styles - DO NOT REMOVE! */
But CSS comments are inherently meaningless, unlike HTML comments. An HTML comment becomes an actual Node.COMMENT_NODE (i.e. the HTML DOM does change if a <!-- comment --> is added/removed), but CSS comments aren’t parsed into CSSOM nodes. It’s as if they didn’t exist in the source stylesheet at all. Because they’re not meaningful, comments could be deleted at any time to save bytes. It’s not reliable.
Finally, inspiration
To reiterate, we’re looking for something to put in a stylesheet rule that’s simultaneously meaningful and free of side effects. Almost sounds like a contradiction, but it can be done.
After a lot of false starts, I finally found the answer in the CSS Namespaces spec:
In CSS Namespaces a namespace name consisting of the empty string is taken to represent the null namespace or lack of a namespace.
Hold up again: what’s a namespace?
A CSS @namespace rule is rarely used with HTML documents, because it would only be required when a doc contains MathML or SVG elements in addition to standard HTML elements. (Not to say this never happens, it’s just uncommon on the web at large.)
A @namespace rule is like:
@namespace vector url(http://www.w3.org/2000/svg);With such a rule at the top of your stylesheet, you can then style a link inside an <svg> (always treated as in the namespace http://www.w3.org/2000/svg) differently from a link in the rest of the HTML body:
a { color: green; }
vector|a { color: red }Here’s a hideous example of namespaced styles in action:
See the Pen HTML :: @namespace styling SVG <a> vs regular <a> by Sanford Whiteman (@figureone) on CodePen.
Anyway, that’s just to show you the reason @namespace exists. But as noted above, a namespace has an interesting property: if the namespace name (the url(...) part in the example above) is the empty string ("") then it’s like saying “unnamed namespace.”
That is, the CSSNamespaceRule object exists in the CSSOM, but it doesn’t otherwise do anything.
This is perfect for our needs, because it’s not disposable — the parsed stylesheet isn’t the same without it — but it also doesn’t change any styles in practice.
So if you include this at the top of the Slides.com custom styles box...
@namespace SlidesDotComCustomStyles "";... you can target that particular stylesheet from JS, even though its outer <style> tag is indistinguishable from other <style> tags.
Get the code
I wrapped up the logic in a function:
function getStyleSheetsByPrefix(prefix) {
const arrayify = getSelection.call.bind([].slice);
let styleSheets = arrayify(document.styleSheets);
return styleSheets.filter(function (ss) {
let rules;
try {
// accessing getter cross-origin would throw an error
cssRules = arrayify(ss.cssRules);
return cssRules.some(function (rule) {
return (rule.type == CSSRule.NAMESPACE_RULE && rule.prefix == prefix);
});
} catch (e) {
// inaccessible/cross-origin stylesheet
return false;
}
});
}You call getStyleSheetsByPrefix("SlidesDotComCustomStyles") and get an array of matched <style> tags (there could indeed be more than one, as namespaces aren’t forced to be unique).
Now as for when you’d want to have this function on hand in a Marketo context, read the next post!
Notes
[1] <style> elements are supposed to contain valid CSS, but again the HTML parser doesn’t check that directly.
[2] You might notice the feature image for this post says it’s about “CSS and CSSOM stuff.” If you don’t know, CSSOM is the CSS Object Model. That’s the API that gives us programmatic access to CSS from JS, beginning (but not ending) with the document.styleSheets collection. It’s powerful, relatively underused technology and I heartily advise you to learn it!