It’s not made explicit in the docs, but a Marketo CSV import does indeed support values with embedded line breaks as long as you use RFC 4180-style syntax.
If you don’t know, RFC 4180 is the closest we’ve got to an official standard for what a CSV, well, is. The RFC is Informational, so it’s not binding like a true Standard. But it covers a bunch of advanced cases very well, and if you’re writing a thing you call a “CSV parser,” you try to hit as many of its points as possible.
Anyway, in §3.6, the RFC is quite clear about how you put a line break (a.k.a. CRLF, ASCII 13 + ASCII 10, etc.) inside a value without accidentally creating a new line. You just quote the value!

So a live CSV would simply look like this:
Email,Comments
sandy+testmultiline@email.test,"This
Is
Multiline
Data"
sandy+testsingleline@email.test,"This is a single line of data"
In a CSV, quoting a value is the only way for it to contain a literal quotation mark (") or a literal comma (,), but it also allows the value to contain a literal line break, rather than the line break starting a new row in the file.
Blow your mind a li’l bit? ☺
One thing to note
When you look at a Lead’s Activity Log, you won’t see the line breaks, which can be confusing...
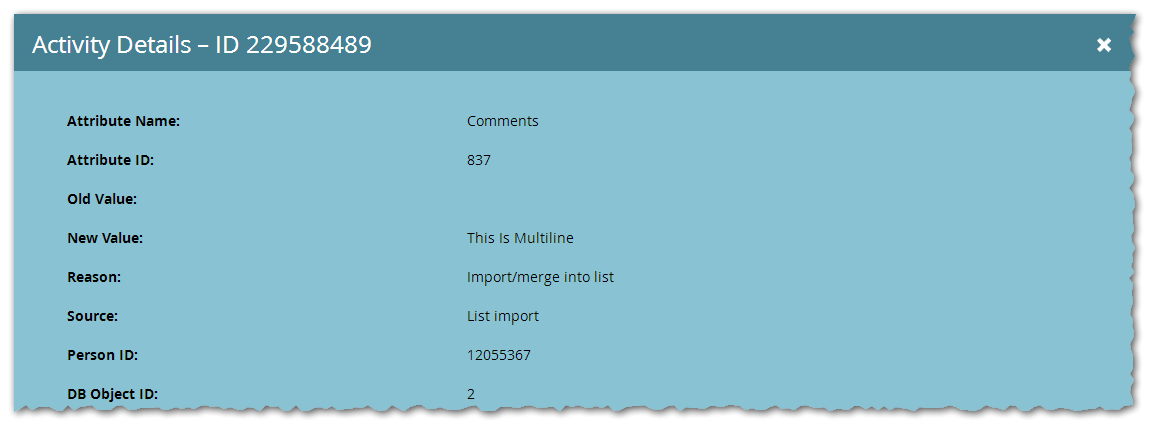
... but they are stored, as shown when you find the field:

This is because the Activity Log (both the full list view and the detail popup) outputs the value inside a generic HTML container, while the lead field editor (or whatever we call that UI!) uses a <textarea>.
And as you already might know, line breaks aren’t displayed in HTML <div>s unless you take specific steps to note that they’re preformatted text. A <textarea> widget reveals that the line breaks are truly there.
While we’re on the topic
I’ve also noticed some people think a quoted value in a CSV means it’s a string, while an unquoted numeric value is a number. This isn’t the case! The values in a CSV are all text values, or let’s say character sequences (just like HTML form fields). They don’t have a datatype until the app that parses the CSV decides to save and/or interpret them as Strings vs. Integers vs. Floats vs. Booleans.
So this row:
"sandy+test0001@email.test",99,33
Is the same as:
sandy+test0001@email.test,"99","33"
It’s up to the app to determine the final datatype of those numeric strings (I’ll refrain from calling them “numbers” to make my point!). For example, merely by inserting a literal '99' into a SQL INT column, you’ve converted it to an INT 99 for when you next read it.
A proper CSV parser uses quotation marks as a guide for separating values from their neighboring text, but not for deciding datatypes.
Note to coders out there
This is why parsing a CSV in all of its possible flavors is more than just .split(/\r?\n/).
Not that I don’t do it that primitive way myself if there’s not a CSV parsing library available. But we have to know that we aren’t supporting all the things users will justifiably call a “CSV.”