On a recent Marketing Nation thread, a developer had questions about the Get Folders API endpoint, one of Marketo’s paginated endpoints that returns folders in batches of (up to) 200:
While paging through /rest/asset/v1/folders.json using the offset parameter, we are seeing duplicate folder ids in later pages that were returned in earlier pages.
e.g. with a maxReturn=200 and offset=0, we get folder id 130 in the results. Then with the same maxReturn=200 and offset=200, we again get folder 130 in the results.
A brief moment of 😵 is understandable, but this behavior makes perfect sense.
See, each page is computed upon request. There’s no pre-computed result set containing all pages as of a point in time. (More on this in the notes.) So the underlying database state can easily change while you’re fetching pages.
Take a folder tree like this:
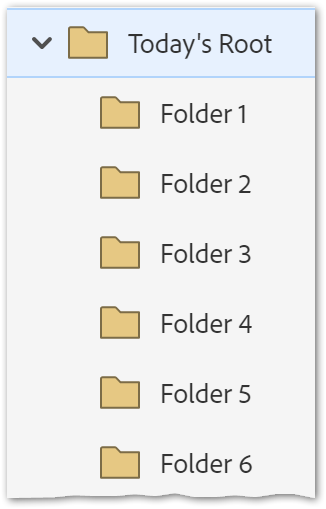
Let’s fetch the root and the first subfolder:
https://123-ABC-456.mktorest.com/rest/asset/v1/folders.json?root=22523&maxReturn=2&offset=0{
"result": [
{
"name": "Today's Root",
"description": "",
"createdAt": "2024-11-28T20:30:17Z+0000",
"updatedAt": "2024-11-28T20:30:17Z+0000",
"url": "https://app-us00.marketo.com/#MF5944A1",
"folderId": {
"id": 22523,
"type": "Folder"
},
"folderType": "Marketing Folder",
"parent": {
"id": 13531,
"type": "Folder"
},
"path": "/Marketing Activities/Default/!Universal/Today's Root",
"isArchive": false,
"isSystem": false,
"accessZoneId": 1,
"workspace": "Default",
"id": 22523
},
{
"name": "Folder 1",
"description": "",
"createdAt": "2024-11-28T20:30:33Z+0000",
"updatedAt": "2024-11-28T20:30:33Z+0000",
"url": "https://app-us00.marketo.com/#MF5945A1",
"folderId": {
"id": 22524,
"type": "Folder"
},
"folderType": "Marketing Folder",
"parent": {
"id": 22523,
"type": "Folder"
},
"path": "/Marketing Activities/Default/!Universal/Today's Root/Folder 1",
"isArchive": false,
"isSystem": false,
"accessZoneId": 1,
"workspace": "Default",
"id": 22524
}
]
}Now get the next 2 subfolders:
https://123-ABC-456.mktorest.com/rest/asset/v1/folders.json?root=22523&maxReturn=2&offset=2{
"result": [
{
"name": "Folder 2",
"description": "",
"createdAt": "2024-11-28T20:30:42Z+0000",
"updatedAt": "2024-11-28T20:30:42Z+0000",
"url": "https://app-us00.marketo.com/#MF5946A1",
"folderId": {
"id": 22525,
"type": "Folder"
},
"folderType": "Marketing Folder",
"parent": {
"id": 22523,
"type": "Folder"
},
"path": "/Marketing Activities/Default/!Universal/Today's Root/Folder 2",
"isArchive": false,
"isSystem": false,
"accessZoneId": 1,
"workspace": "Default",
"id": 22525
},
{
"name": "Folder 3",
"description": "",
"createdAt": "2024-11-28T20:30:51Z+0000",
"updatedAt": "2024-11-28T20:30:51Z+0000",
"url": "https://app-us00.marketo.com/#MF5947A1",
"folderId": {
"id": 22526,
"type": "Folder"
},
"folderType": "Marketing Folder",
"parent": {
"id": 22523,
"type": "Folder"
},
"path": "/Marketing Activities/Default/!Universal/Today's Root/Folder 3",
"isArchive": false,
"isSystem": false,
"accessZoneId": 1,
"workspace": "Default",
"id": 22526
}
]
}Now someone creates a new subfolder, Folder 2.5, while we’re running our job:
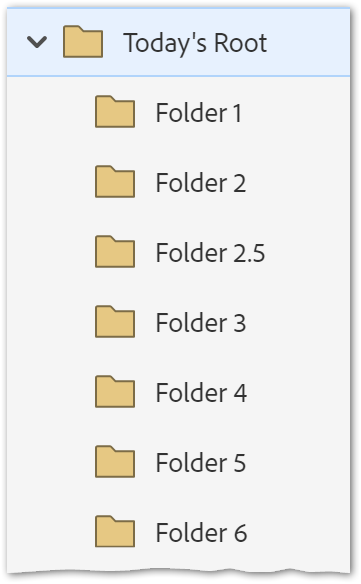
And when we get the next 2 subfolders from our last offset, we see Folder 3 again!
https://123-ABC-456.mktorest.com/rest/asset/v1/folders.json?root=22523&maxReturn=2&offset=4{
"result": [
{
"name": "Folder 3",
"description": "",
"createdAt": "2024-11-28T20:30:51Z+0000",
"updatedAt": "2024-11-28T20:30:51Z+0000",
"url": "https://app-us00.marketo.com/#MF5947A1",
"folderId": {
"id": 22526,
"type": "Folder"
},
"folderType": "Marketing Folder",
"parent": {
"id": 22523,
"type": "Folder"
},
"path": "/Marketing Activities/Default/!Universal/Today's Root/Folder 3",
"isArchive": false,
"isSystem": false,
"accessZoneId": 1,
"workspace": "Default",
"id": 22526
},
{
"name": "Folder 4",
"description": "",
"createdAt": "2024-11-28T20:31:02Z+0000",
"updatedAt": "2024-11-28T20:31:02Z+0000",
"url": "https://app-us00.marketo.com/#MF5948A1",
"folderId": {
"id": 22527,
"type": "Folder"
},
"folderType": "Marketing Folder",
"parent": {
"id": 22523,
"type": "Folder"
},
"path": "/Marketing Activities/Default/!Universal/Today's Root/Folder 4",
"isArchive": false,
"isSystem": false,
"accessZoneId": 1,
"workspace": "Default",
"id": 22527
}
]
}Similarly, deletes while a paginated job is running can change the overall result if folders slide backward out of view.
These are just things you must expect in order to build a resilient Marketo integration. An ostensibly “full” Get Folders job isn’t guaranteed to include all folder IDs that existed when the job started. Nor is it guaranteed to include a given folder ID only once.
Mitigation tactics
You can mitigate the impact in a few ways:
- sync more frequently: this keeps your users happier either way
- parallelize: use 2 workers to fetch data — staying under the 100 calls/20 secs rate limit, of course — to speed up the whole job
- re-crawl from programs: periodically run Get Programs using a recent date range filter, then crawl backwards from each program to get its ancestor folders (not exactly the same as getting recent folders, but fills many gaps)
- acknowledge the possibility in your product docs, but don’t worry about it (far better than nothing!)
Notes
Get Folders uses a basic paginated model akin to OFFSET/LIMIT in SQL. Because it’s stateless, your app doesn’t need to know anything about the next request other than the offset (and in fact that statelessness allows for parallelization, within limits).
In contrast, stateful models such as keyset pagination ensure consistency across multi-page jobs, but they require server-generated pointers to each page and are more complex to implement. Marketo uses a similar approach for the Activity API, paging tokens.
One rarely used model is where the server fetches the full result set in response to the client requesting a single page. Results can even begin streaming while being cached on disk, like atee; HTTP range lets you fetch file chunks without additional overhead. In theory at least, that’s the best of both worlds! Problem is it doesn’t scale: disk storage quickly grows out of control, and you waste resources generating data that may never be used.