Companion post on non-JSON data tokens (i.e. CSV or other formats) is here.
You can store JSON blocks as Text {{my.tokens}}, then embed the tokens in LPs to enable advanced dynamic content.
This works fine in your browser, where the JSON is actually used, because Marketo leaves the token text largely as-is (line breaks are stripped, but that's okay as it doesn't change the JSON data).
Problem is, it's impossible to read, let alone edit, in the Marketo UI:

This makes it really hard to spot-check/last-minute-adjust the values in these tokens.
So you'd naturally think a Rich Text token could serve the same purpose, plus give you the multi-line editor that's a zillion times easier to use.
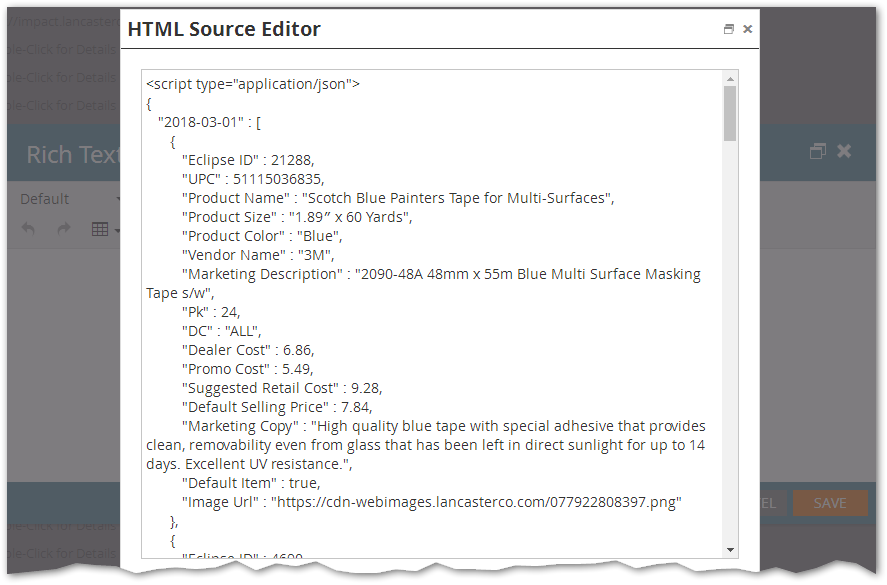
This looks good at first, but once you save the token, Marketo wraps the script in a pesky (and in fact unnecessary) CDATA section:[1]
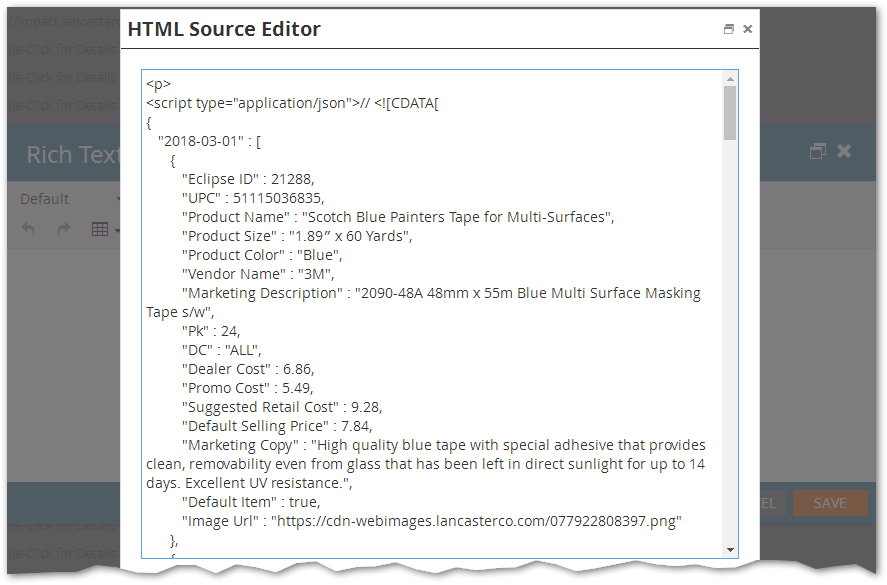
Now, you've got a problem, because valid JSON can't start with // <![CDATA[ nor end with // ]]>. That stops you from just grabbing the text inside of the <script> and running JSON.parse() on it to get a live JavaScript object (with nested arrays and objects and all that fun stuff).
Instead, you need to trim off the first line and the last line before parsing.
All the trimmings
Here's a tight little snippet to trim the unwanted CDATA lines and parse the JSON:
var jsonText = document.querySelector("script[type='application/json']").text
.split(/^/m)
.slice(1,-1)
.join("");
liveJSONObject = JSON.parse(jsonText);
Let me walk you through it. It's pretty cool, I must say:
- retrieve the raw
textof the<script>tag - split the text into an array of lines (
/^/mis amultiline split) - slice off the first (
1) and last (-1) members of the array - re-join the lines
- parse the result
What I didn't do
You might wonder why I chose the methodical (though, I think, quite understandable) split-join method instead of, say, a super-awesome regex.
It's because regexes are not a good call for every situation. Even regex masters agree that sometimes, you need to iterate, split, map, etc. — for code readability if nothing else.
But if you insist, here's a much more cumbersome way to attempt this with a single regex (in fact, I don't even know if this is error-free, as I stopped working on it when the regex escapes became unreadable and went with the above!):
var jsonText = document.querySelector("script[type='application/json']").text
.replace(/(^\/\/\s*<!\[CDATA\[)|(\/\/\s*\]\]>$)/g,""),
liveJSObject = JSON.parse(jsonText);
Burying the lede
I didn't want to distract you before, but you might have wondered what <script type="application/json"> is all about.
You're familiar with simply <script>, shorthand for <script type="text/javascript">. Well, a <script> tag with an explicit non-script MIME type (a type other than something/javascript) is known as a data block. (I also call them “data islands” after the old IE feature by that name.)
And this isn't just a cool hack, it's a standard! Little-known perhaps, but in the HTML5 standard data blocks are explicitly documented.
What's it all for, though?
You might still wonder what you can do with JSON in {{my.tokens}}. Well, here's a Marketo LP at one of my clients:

And when you output a JSON token into the page and run it through a little Pure microtemplate, the page becomes:
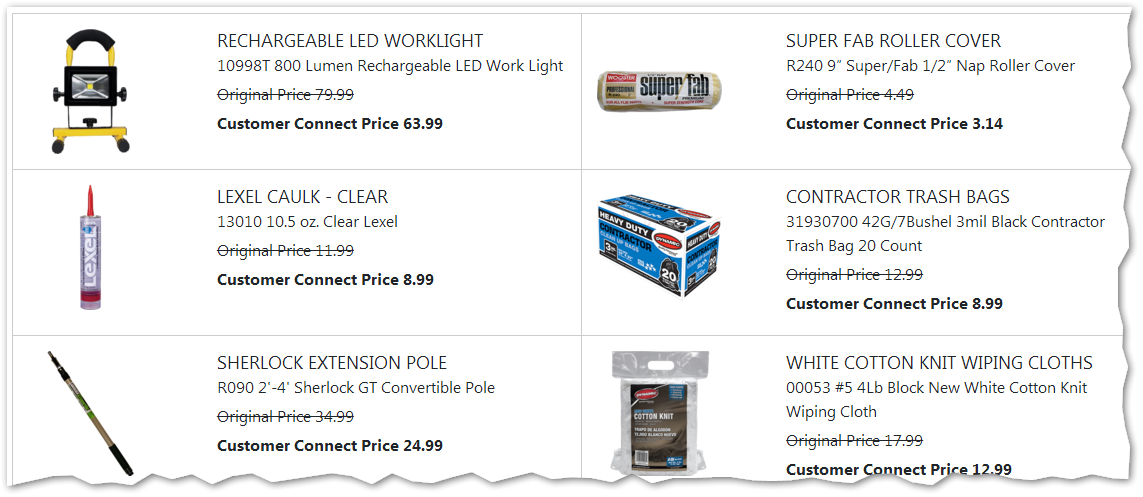
You can, I hope see the appeal (in this case the JSON is populated via a Marketo API call from a product database, allowing the pages to be hyper-dynamic).
What about non-JSON data?
Here's a short follow-up post on that.
Notes
[1] This ancient commented-CDATA method of wrapping JavaScript is not necessary on Marketo LPs, period. And it's scarcely relevant across the web as a whole, since it relates to the effectively-dead XHTML effort. You can read some of the old justifications here.