Serverless functions can be a good choice for custom integration jobs. After all, it’s a waste to keep a server up 24/7 just to import stuff into Marketo once a day.
Instead, run a function at 2:00am (you can even use an outbound webhook as your scheduler). That’ll spin up an instance to run the job, then it’ll spin down on its own.
One hitch: a serverless function’s environment cannot be expected to persist across executions, even if it sometimes does.[*] That means if you want to remember the last successful import timestamp/checkpoint — and you typically do! — you need a place to reliably store that data.
Suddenly, you wonder if your architecture is a bit too transitory. You start hunting for a cloud database just to store a few values (or a cloud filesystem to store a .lastrun file, but same idea).
What if I told you Marketo itself could be that database?
Standalone custom objects to the rescue
With Marketo Custom Objects, we think of 3 effective types:
- simple objects with a link to people or companies, the one-to-many setup
- junction (a.k.a. xref) objects in a many-to-many setup, with links to people/companies and to a base object
- base objects in a many-to-many setup, linked to by a junction object
But there’s (implicitly) a 4th type, too. By default, an object has no outbound links, and if it doesn’t have any inbound links either, we call that a standalone CO. (It’s the same as a base object ③ before you build the junction object.)
Until today, you probably thought such an object was just “incomplete.” But here’s the thing: standalone COs are fully readable and writable via the REST API. And the fact they aren’t attached to a person is good for today’s purpose, because it means they can’t accidentally be deleted!
They essentially are a side-by-side data store that can hold metadata about other objects (either custom or system objects) without any fear of them being deleted, or even viewed, by everyday Marketo users. Not to overstate the case, but they’re magic.
Here’s a standalone object Custom Object Sync Metadata which we use to store the last state of our import jobs:
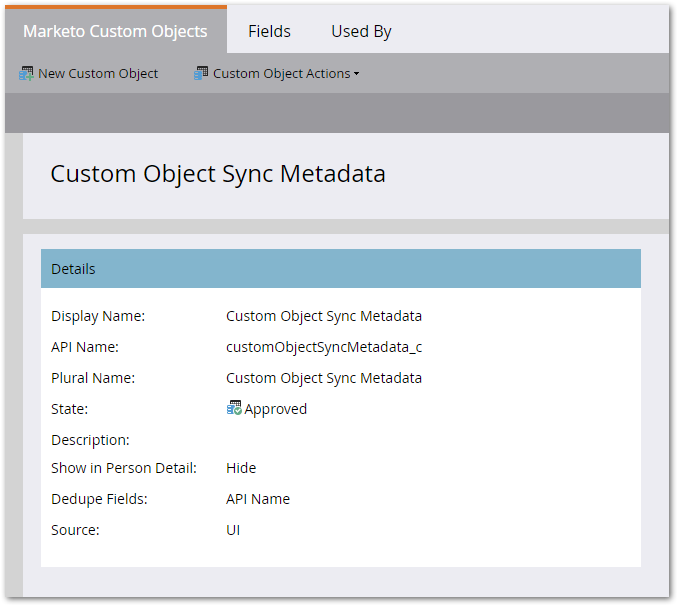
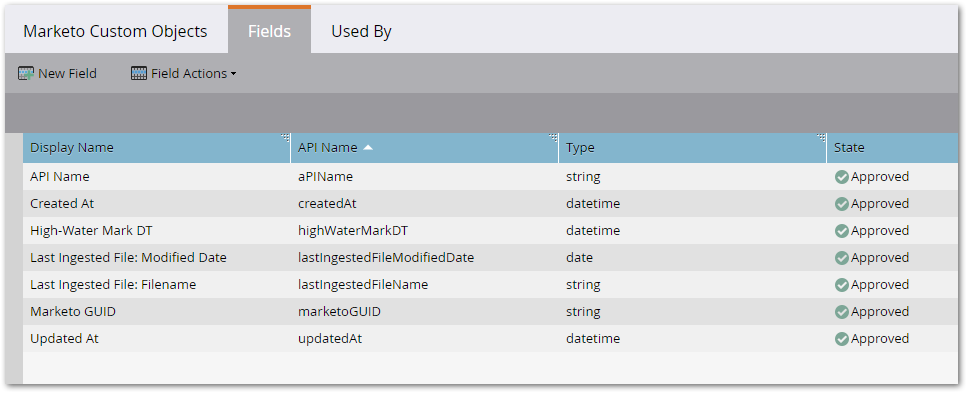
As you can see, the dedupe field is API Name, so there’s one consolidated metadata record for every object we import. High-Water Mark DT is the most important field: that’s the systemmodstamp of the last imported record.
Let’s say we want to get the info for the object Implemented Product so we can pick up where the last job left off:
/rest/v1/customobjects/customObjectSyncMetadata_c.json?filterType=apiName&filterValues=implementedProductV1_c&fields=highWaterMarkDT,lastIngestedFileName{
"requestId": "1b93#18c9dda2ff6",
"result": [
{
"seq": 0,
"marketoGUID": "c0bfd9e4-a814-4b6f-a2f0-f2d8c09736dd",
"lastIngestedFileName": "c:\\something\\else\\file.txt",
"highWaterMarkDT": "2023-12-24T12:34:56Z",
"aPIName": "implementedProductV1_c"
}
],
"success": true
}The Custom Object Sync Metadata can be fleshed out with other useful fields:
- Last Ingested File: Number of records
- Last Ingested File: Ingested At
- Epoch Started At (if you separately drop an entire custom object you want to reset its “date of birth,” if you will, which we call an epoch)
- Total Records in Epoch
The CO can’t log fully-fatal errors
By definition, if you can’t access Marketo at all, then you can’t log the job state to Marketo!
So this approach doesn’t cover such catastrophic error cases. It can only log import successes and exceptions when the Marketo REST API is generally available. But you already have SMTP/SMS alerts built into your code for those other cases, right? Right? 😊
Notes
* For example, in AWS Lambda, global variables can be used as a cache. They’ll still be around on subsequent invocations, provided the instance doesn’t spin down due to low load. But you can’t guarantee you’ll get a “primed” instance next time. So you use the cache if you get lucky, but you need to build for the unlucky case, a cold start.