In an upcoming blog post, I’ll show how to add a character counter feature to Textarea fields like so:
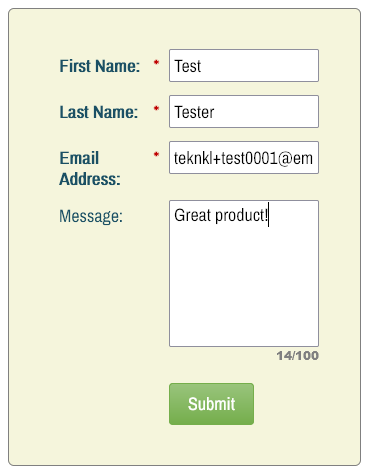
(Yep, it offers “chars remaining” mode as well as “used chars/max chars” mode.)
While working on that code, I realized people who say “I want to display a counter based on the maxlength attribute of the <textarea>” probably don’t know what’s actually being counted.
maxlength, briefly
The maxlength attribute is clearly defined in the HTML5 spec. It applies to <input> boxes as well as <textarea> elements and has the same meaning in both cases:
A form control maxlength attribute, controlled by the dirty value flag, declares a limit on the number of characters a user can input. The number of characters is measured using length Follow the hyperlink for length and you’ll see:
A string’s length is the number of code units it contains.
With code unit defined as:
A string is a sequence of unsigned 16-bit integers, also known as code units
If you still don’t get what code unit means, but you’re the optimistic type, maybe you figure that’s just nerd-speak for “character” and go out about your business. But it’s much more complex than that.
Let’s take a look
For reference, here’s the HTML for the <textarea> in the screenshots below.
<textarea id="userquestions" name="userquestions" rows="6" maxlength="100"></textarea>(Limit the the visible rows to 6, limit the length to 100 code points.)
Exhibits I and II
These first screenshots should give a clue as to what we’re heading into:
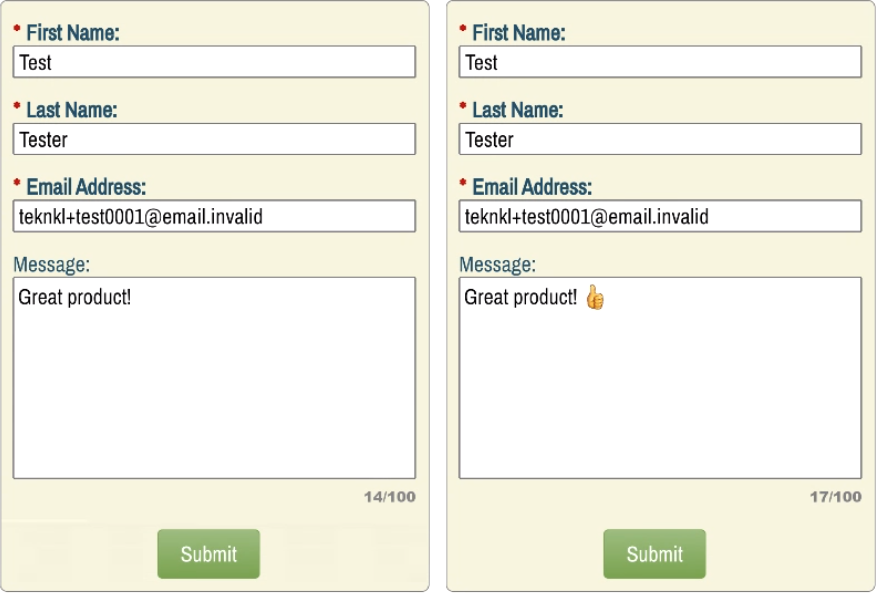
On the left, the 14 Latin-1 characters:
On the right, those same 14 characters. Then a space. Then a single emoji: the standard thumbs-up. So 14 + 1 + 1 = wait, 17?
Well, yeah.
See, the thumbs-up emoji is Unicode 1F44D. That’s decimal 128,077 — meaning it’s well outside the range that can be represented by one 16-bit code unit. (16-bit positive integers only range from 0-65,335.)
As a result, like all true Emojis, it takes at least 2 code units to represent. Those code units are computed using the surrogate pair algorithm.
You don’t need to know the details of the algorithm, but it but boils down to this: you end up with 2 adjacent code units, each less than FFFF (65,335), that together represent the Unicode code point 1F44D (128,077).[1] The first one is called the “high surrogate” and the second the “low surrogate.” Only in that order are they combined to represent the larger number.
In the case of the thumbs-up, the high surrogate is D83D (55357) and the low is DC4D (56397). Remember, these are the bits and bytes under the hood. To the end user, it’s just a single emoji.
But it gets even more weird.
Exhibits III and IV
Check out these next screenshots:
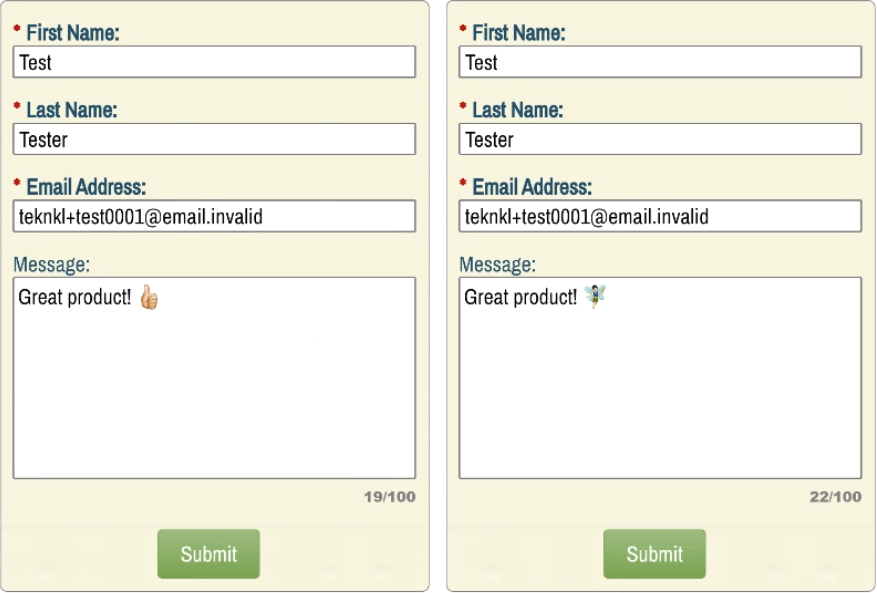
On the left, I’ve chosen the thumbs-up emoji with a specific complexion (I’m very pale!) instead of thumbs-up in default/yellow style.
On the right, a fairy emoji with both complexion and gender variation.
So the thumbs-up emoji, just by being Fitzpatrick Complexion Type-1-2 (that’s the technical name), takes up a 4 code units out of the 100 allowed. And the fairy takes up a full 7 code units!
Yep. You could fit 100 letters A-Z in the box. But only 25 thumbs-up and only 14 fairies.
Let’s look at why.
Complexions are a whole separate character
Complexions were added to Unicode in a smart way. Instead of creating new code points for every combination (which would’ve been impossible to maintain) the complexion is a modifier character that immediately follows the emoji.
So a “complexion-ed thumbs up” is literally a thumbs up followed by a complexion character. On platforms (like Firefox desktop) which support the individual characters but don’t combine them visually, it looks like this:

That’s 1F44D followed by 1F3FB. Both of those require a surrogate pair, so 4 code units total.
Gendered and complexion-ed emojis have even more complexity
You might think the complexion-ed fairy would also take 4 code units. But it’s even more elaborate, because the fairy has an explicit gender.2
The gender of an emoji is indicated by reusing the female sign ♀ as if it were a combining character, even though it’s a Unicode code point on its own (and a quite venerable one, from 1993).
In order to merge the gender with the preceding character(s), you insert a Zero-Width Joiner hint (ZWJ) first. Translation: “Merge the character after the ZWJ with the character before the ZWJ, to the degree it’s graphically feasible.”
And that’s not all! You also need an Emoji variation selector after the female sign in order to indicate that the most colorful/dimensional form of the code point should be used.
So in total, you have:
1F9DA (Fairy) + 1F3FB (Fitzpatrick complexion Type-1-2) + 200D (ZWJ) + 2640 (Female sign) + FE0F (Variant selector-16 for Emoji variant) = 7 code units.
Note the last 3 code points are within the BMP, so they only take 1 code unit each.
It wasn’t always like this
Interestingly, in a Last Call Draft of W3C HTML5 from 2011, the maxlength attribute counted code points, not code units. Back then, it said:
... if the code-point length of the element's value is greater than the element's maximum allowed value length, then the element is suffering from being too long.
With code-point length defined as:
the number of Unicode code points in that string
But as the W3C spec evolved (and is now merged with the WHATWG branch) that requirement was changed. As we’ve learned in this post, even switching to code points wouldn’t reflect the end user’s notion of how many “characters” they’ve input, since combining characters throw that completely out of whack.
So is maxlength useful?
Definitely!
It’s most useful (mandatory, in fact) if you’re trying to limit the number of code units passed to your server because your back end database also restricts the length of the field in code units. For example, your SQL server probably allows you to store 100 code units (or 100 byte pairs, same thing) in an NVARCHAR(100) column, not 100 characters. So it makes perfect sense to count the same way on the client and the server.
And even if your back end is practically unlimited, you still want to discourage users from writing a novel.
On marketing forms, 99% of the characters entered will take only 1 code unit.[3] This is true even if you’re expecting Chinese input: some Chinese characters take 2 code units, though the vast majority take only 1. And a few scattered emoji won’t make a practical difference as long as you allow maxlength of, say, 255.
But for real apps, you’d likely want a string like “😄😄😄😄😄😄😄😄😄😄” to have the same effective length as “ABCDEFGHIJ”. In that case you should use custom code that counts code points, rather than maxlength.
The holy grail: counting grapheme clusters
Rather than counting code units or code points, grapheme clusters are the ideal way to limit input length, since that’s what end users think of as a “character.”
But designing a cross-browser input that counts clusters would be really tricky, since browsers don’t offer the all-important \X regex matcher. I’m not gonna even try... until the next time I can’t sleep.☺
Notes
[1] Do keep in mind what the UTF-16 surrogate pair concept isn’t: it isn’t one big 32-bit number. That would be UTF-32.
[2] In the Unicode standard, it’s more sex than gender. But it’s come to include both meanings.
[3] A lot of decomposed strings, which I’ll write about later, can disrupt this assumption. But those would likely be pasted in, not typed.