Most users know that Marketo usually retries email sends for 24 hours.[1] If neither a fully-successful nor fully-failed SMTP transaction can be completed in that time, the email will Soft Bounce.
But what does it mean to “retry for 24 hours”? Are there tens of thousands of attempts, the server retrying right after the previous attempt fails? (Yikes, no.) Does it try every hour on the hour? (Also no.)
The question comes up occasionally, and it’s good to have at least a rough answer.
For example: sales complains a contact didn’t get that day’s cast. After way too much hold music, you find the contact’s IT team disclosed mail problems earlier in the day, but they’re now resolved. The last Activity Log entry is Send Email.
How do you intuit what Marketo is doing under the hood and give a prediction for when they might get that still-queued email? Last thing you want to say to the boss is, “I don’t know, maybe we should resend?” and then end up looking foolish because they get the email twice.
Watching Marketo’s back(off )
All mailservers — this isn’t just a Marketo thing! — use what’s called an exponential backoff algorithm for retries.
A backoff algorithm uses purposely irregular retry intervals instead of exactly every 5 minutes for 24 hours, or every 60 minutes for 48 hours. The interval expands, and potentially contracts, based on a combo of previous results and current conditions.
The theory goes: at the start, you retry relatively quickly, 5m or less. If there’s another transient error, you double the interval to 10m, and if there’s still an error, you double again.
With each error, you give the servers (both yours and theirs) more and more time to recover. You extend the intervals between retries because (a) you’re potentially wasting your own network/disk/CPU resources on another failed connection and (b) you’re hammering a server that may be struggling to stay up, which doesn’t help anyone.[2]
By the end of the the 24-hour period, there’ll be several hours of wait time. In the middle, delays may be randomly shifted around to spread the load, though won’t ever be as short as at the beginning.
Also note the backoff algorithm defines a baseline retry schedule. Retries are inherently constrained by local resources as well. If a queue is extremely busy, retries must wait longer than the algorithm alone would predict.
A couple of real-world examples
To observe Marketo’s backoff algorithm, I set up a dummy SMTP server that drops every connection before any data is sent and watched the logs. (It doesn’t reject the message itself, because you don’t want an immediate Hard Bounce. It just says “Yes, I’m here, but go away for now.”)
Here are the packet traces (because I’m cool like that) from 2 sends to the same address on 2 different days:
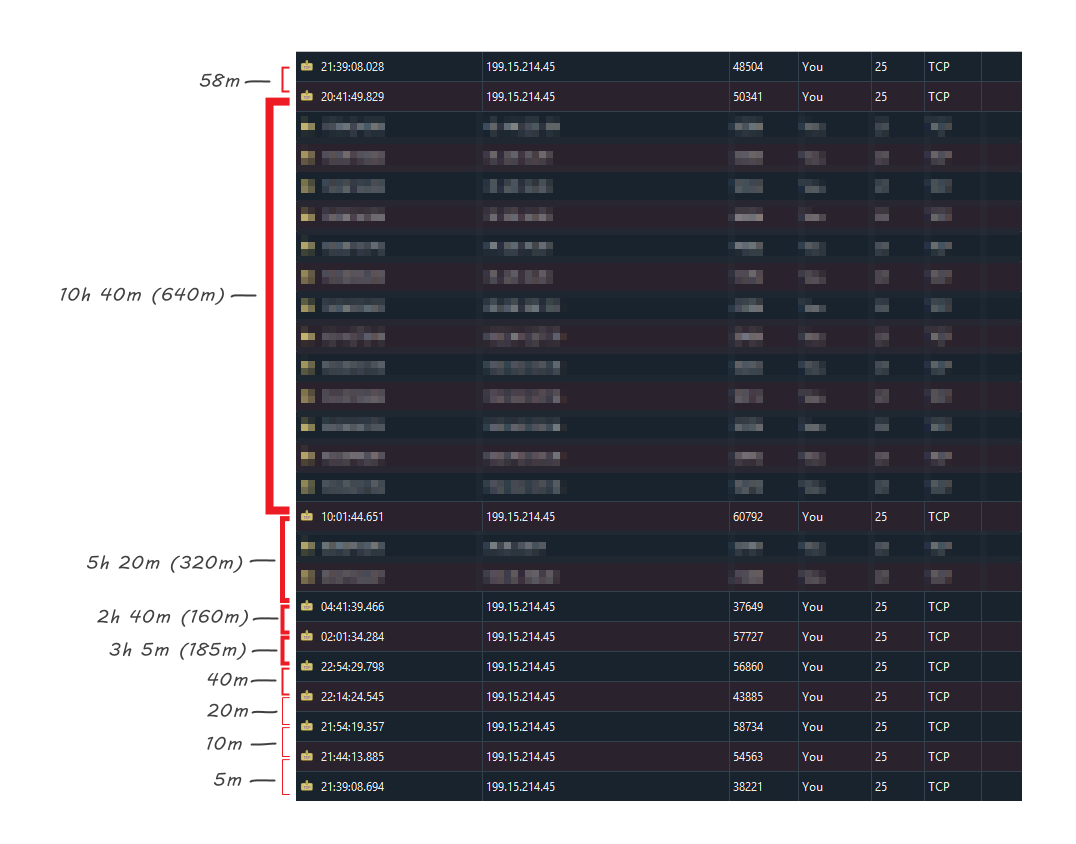
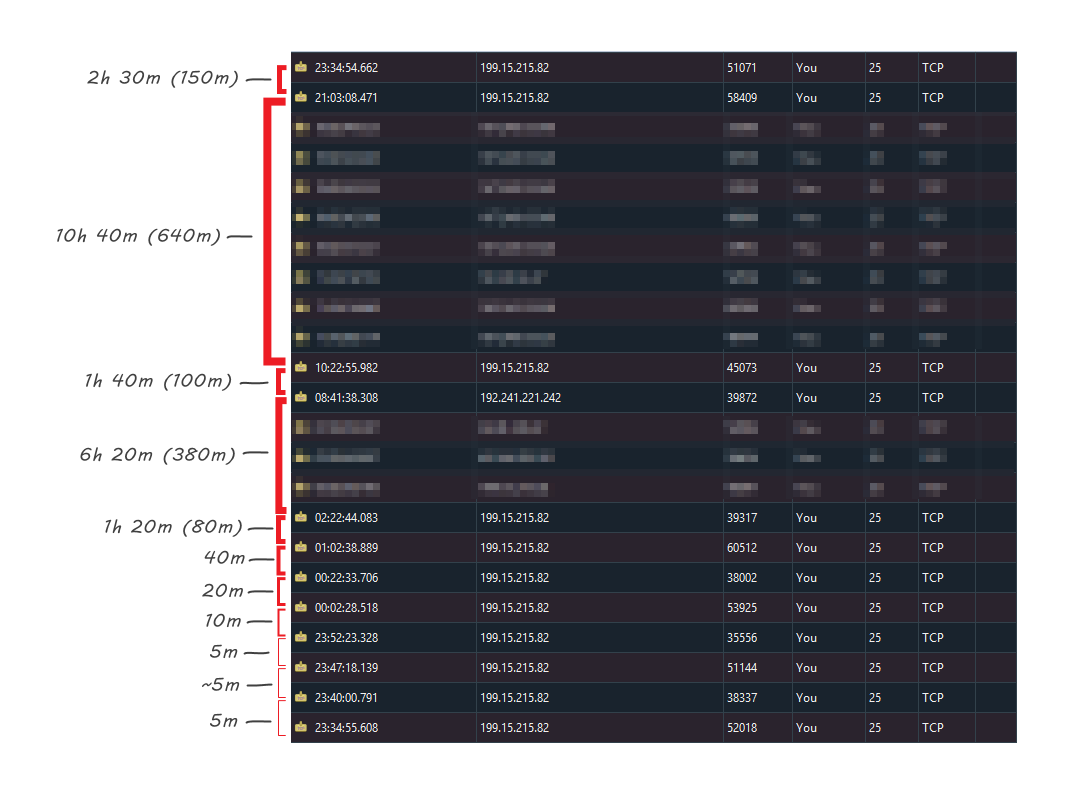
It’s interesting that the traces are very similar yet not identical.
- The first send extends the retries immediately, more closely following the exponential concept.
- The second send lingers on 5-minute retries at the start, but eventually scales up as expected.
- Both have an exactly 10h 40m delay before the next-to-last try, then “hurry up” to get one last try in before the end of the 24-hour period.
- In the middle stretch, they always wait at least hour, but presumably due to a busy queue and/or explicit resource limits the distribution is uneven.
So while you can’t be 100% sure what’ll happen on Day 𝑋 with Recipient 𝑌, you’ve got some good info to give the boss!
Notes
[1] To most domains. There are a few special domains that are tried for longer because of known congestion.
[2] The exponential backoff concept isn’t great if a server is coming up for a few solid hours at a time, then going down for a few hours. As the interval between your retries grows, you’re less likely to hit the sweet spot and be trying at the same time they’re up. But that’s kind of the nature of the beast.