Love seeing surprising-but-correct behavior in the wild, ’stead of just proving in the lab that it could happen.
Today, a client finally asked “Why doesn’t this person show up when we search Marketo?” and the explanation was in this post I started years ago. It felt too theoretical back then, but now it’s coming out of Drafts.
They have a record like this in their database, First Name Étienne and Last Name Chateliez:
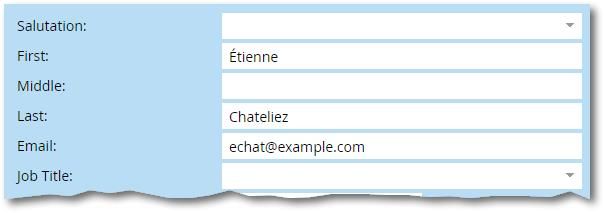
And yet filtering on what seem to be those same values:
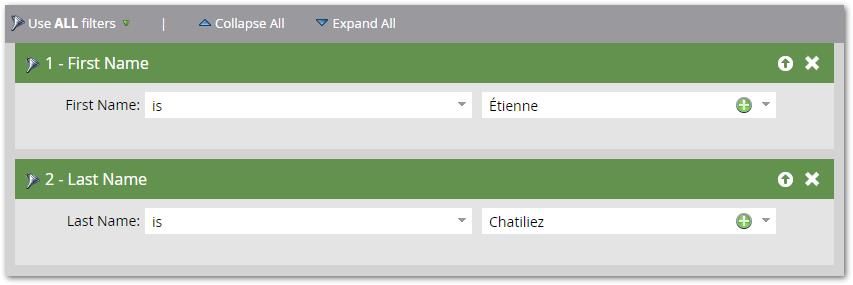
Brings up the surprising:
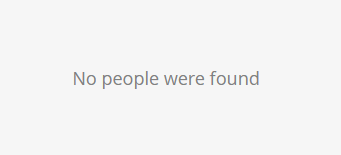
And no, this isn’t about Smart List caching. It’s about something way more interesting.
The most common Latin-1 accented characters have two forms
What’s the length, in characters, of the following value, including spaces?
Tony! Toni! Toné!
You’re thinking 17. Now, how about this one?
Tony! Toni! Toné!
You’re thinking 17 again, but you also want to say Is this a trick question?
Correct, I’m trying to blow your mind. The answers are 17 and 18, respectively. Huh?
The strings look exactly the same, to the letter. They’re not merely similar. Nor is there zero-width whitespace or anything of that sort. Every letter (or “grapheme” or “glyph”, for today’s purposes there’s no difference) is the same.
That includes the next-to-last letter. In both cases, it’s a lower-case e-with-acute-accent, as used in many languages. But the first é is 1 character long, as it looks to the naked eye. The second é is visually identical, but is 2 characters long under the hood!
Again, to be clear, these letters aren’t mere homographs — where one is borrowed from Klingon or something and has a slightly different width or accent placement that you can’t see until you blow it up 1000x: they are literally the same letter, visually and semantically.
They’re an e-acute generated in different ways, both of which happen in the wild, and which will drastically change your concept of “equal values.”
The 1-character é is known as the Precomposed (a.k.a. Composed, or Normalization Form C/NFC) form, while the 2-character é is the Decomposed (Normalization Form D/NFD) form of the same letter.
The Precomposed form is all-in-one, while the Decomposed is an unaccented e followed immediately by a combining acute accent. They both represent the same letter and are defined as canonically equivalent in the Unicode standard.
Surprises ensue
The two ways to spell “Toné” or “Étienne” lead to surprises:
- Most important, the two strings are not equal. A standard equality check using
==or===or.equals()or a Smart Listisor whatever your language/app offers will fail. Alternative comparison methods[1] exist but not with commercial apps, only code you write yourself. - The Decomposed string may exceed length limits while the shorter will not. For example, if your form has an
<input maxlength="17">the person can’t type the Decomposed version in the box. (Same goes on the server side: a database is going to count the Decomposed version as too big for aCHAR(17)column.) - The Decomposed string is not a Latin-1 string. The combining accents are outside the Latin-1 range so you can’t assume “Western European words are always Latin-1.” This was actually why I put this post together back in the day: saw some badly broken JavaScript on a major site that didn’t take this into account.
Unless you’re supremely careful, you’ll have both versions in your db
You can easily standardize Marketo form fill data on one version or the other — usually Precomposed/NFC, since it’s more space-efficient. Code for that is below.↓
But standardizing lists, from the usual chaotic sources, on only one version? That’s tough. If you pass every list through a pre-processing app (good idea by the way!) you can solve it. But you can’t have any procedural leaks, i.e. people uploading directly to Marketo.
Leads created by 3rd parties using the REST API are probably the trickiest, since you’re unlikely to have the ear of their engineers and they’re probably not aware of the issue (sad but true, only encoding-obsessed people know about it).
After the fact, a webhook-powered service like FlowBoost can convert values to one form or the other, but you have to trigger on changes to any field that might hold accented characters. That’s a lot to ask of a Marketo instance.
So, bottom line: unless you make it a priority, you’re going to have Precomposed and Decomposed versions throughout your db.
So you’re just trying to scare us?
Well, you have me there! Without a full-spectrum solution, I’m pretty much saying Keep this crazy case in the back of your mind. When a Smart List filter doesn’t match, it may not be Marketo being weird, but rather the whole world of encoding being weird.
Solve it for forms, at least
For forms, just give string fields a once-over before submitting:
/**
* Normalize string fields to NFC
* @author Sanford Whiteman
* @version v1.0 2023-08-19
* @copyright © 2023 Sanford Whiteman
* @license Hippocratic 3.0: This license must appear with all reproductions of this software.
*
*/
MktoForms2.whenReady(function(readyForm){
readyForm.onSubmit(function(submittingForm){
const originalValues = submittingForm.getValues();
const normalizedEntries = Object.entries(originalValues)
.filter( ([name,value]) => typeof value == "string" )
.map( ([name,value]) => [name, value.normalize("NFC")] );
const normalizedValues = Object.fromEntries(normalizedEntries);
submittingForm.setValues(normalizedValues);
});
});Technically, this code touches more than text fields. It’ll also standardize Radio, single-valued Select, and single-valued Checkboxes fields, none of which are user-editable — that is, end users can’t alter the value in the first place. But it’s harmless, and looking up the input type would require more code for no practical gain.
(In contrast, if you were doing a wholesale standardization of your entire database you definitely want to update only fields that need it. For example, check if a field is already normalized by checking if value === value.normalize("NFC") and skip if so.)
Notes
[1] JS String.prototype.localeCompare must see them as equal per the spec. Recent versions of Postgres and Oracle let you test NORMALIZE('string') = NORMALIZE('string') but other SQL engines do not.