Grab Images from Web (under Email Editor » Email Actions and the equivalent spot in LP Editor) is a cool tool, but it’s subject to common web security restrictions.
So a page that looks fine in its own browser tab — like your own corporate site, the principal place you’d (legally) grab images from — can nevertheless return an error when you try to scrape its images from the Marketo UI:
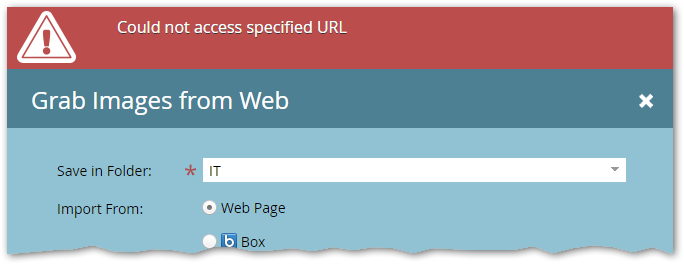
There are a few possible causes (more than one may apply):
- the site requires the Referrer of image requests to match its own origin, an age-old way to block hotlinking
- the site requires a session cookie of some sort, even if it’s not an authenticated session
- the site uses other mechanisms to detect and reject spidering attempts
With Grab Images From Web, Marketo’s back-end server makes an HTTP GET request to the site. This is an anonymous, direct request with no Referrer.
So even if you’re logged into the remote site in your browser, that doesn’t make a difference, since Marketo doesn’t send any credentials along with its request.
Explaining partial results
Even when Grab Images connects to the site successfully, it still may not return all the images you see in your browser.
The feature looks for <img> tags and CSS background-url sources in the original HTML, but it won’t find images that are dynamically injected using JavaScript new Image() or other DOM injection methods. It’s an old-school web spider, in other words.